ML causal testing
| GitHub |
|---|
Summary
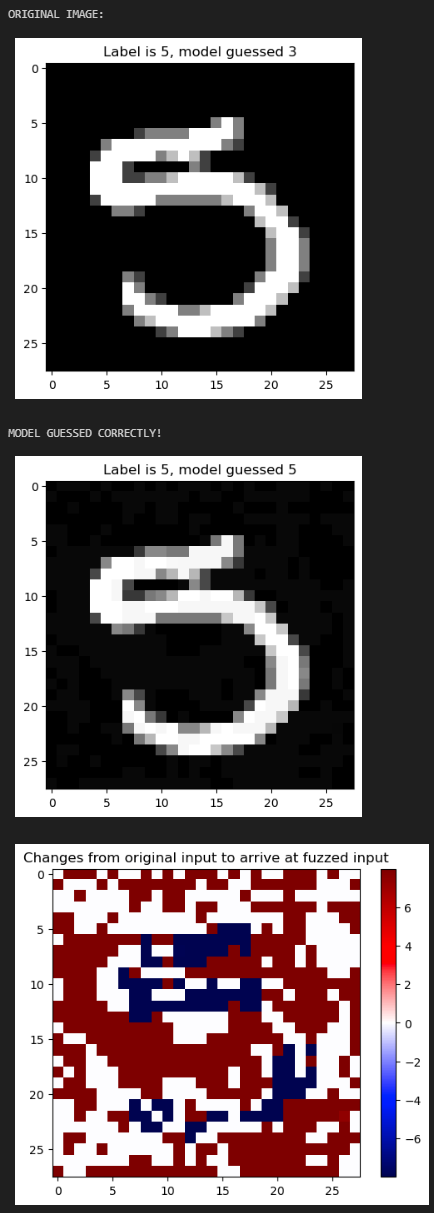
Determining the root cause of a unit test failure usually takes up a significant portion of debugging time. And when training machine learning models, finding the root cause can be especially time-consuming, as these models tend to be black boxes. I worked as a paid researcher in the INSPIRED Lab of Dr. Brittany Johnson at George Mason University to develop a tool called py-holmes-dl, which streamlines the debugging process for neural nets by showing developers exactly what dimensions of the input their model failed to attend to. I will be first author on an upcoming paper discussing this tool.
At time of writing, user testing of py-holmes-dl is still under way, so the tool and its paper have not been released to the public yet. When they are, py-holmes-dl will be available on the lab's GitHub page above.
A non-deep-learning version of the tool is already available via this link. Dr. Johnson previously developed a version of the non-deep-learning tool for Java, called Holmes.
Skills gained
I've learned a lot about UX research by undertaking this project. I've written scripts for user tests and interiews, identified end user personas and determined pain points, and learned to use Atlas.ti, DoveTail, and EnjoyHQ to code qualitative data.
By conferring with faculty experts in various machine learning models and applications, I've broadened and deepened my knowledge of the ML landscape and how to implement ML models.
By using tools such as caches to read the user's project files in minimal time, I've been consolidating my past experience in optimization.
I've become proficient with using Git Bash, which allows for easy updating of a GitHub repository.
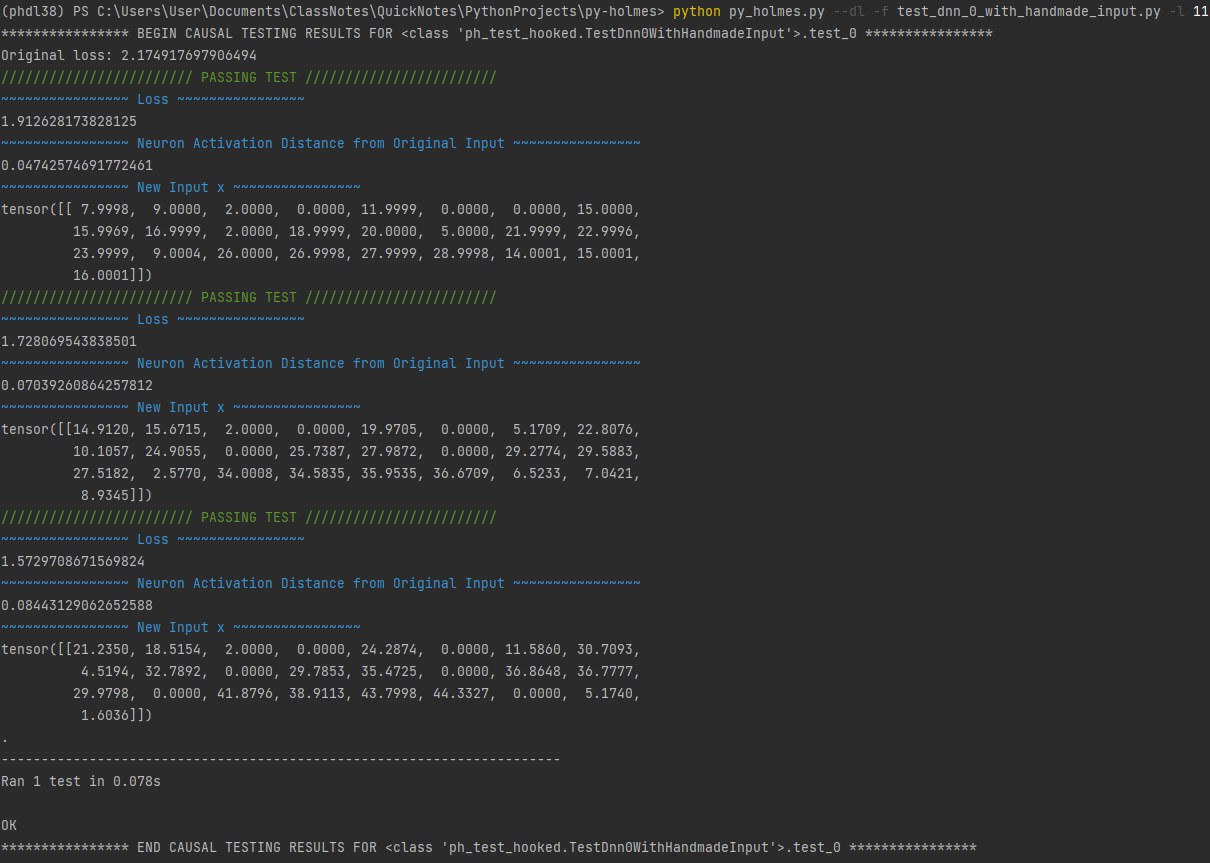
I've learned how to read, parse, and modify abstract syntax trees and execution traces (such as the one excerpted below), which are necessary in extracting information from the original failing test and generating similar tests.